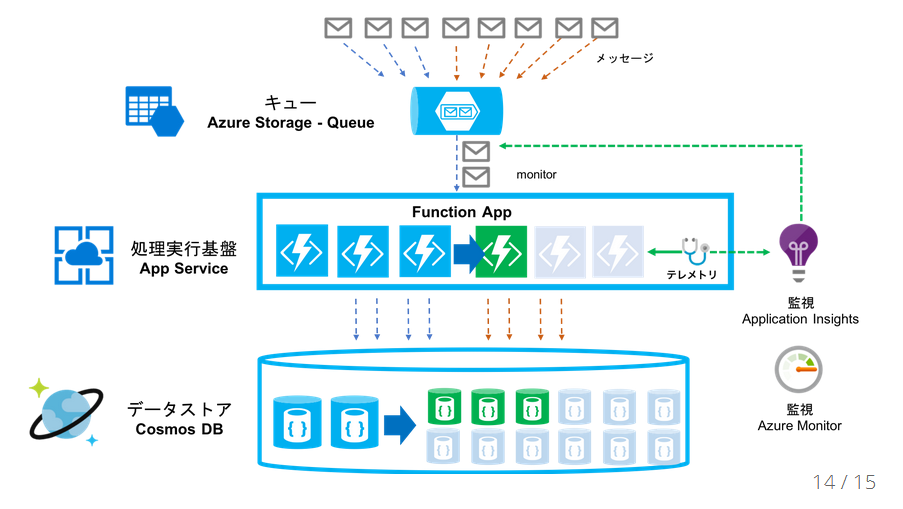
前回少し書いた、最終課題について概要を書きます。
技術的に詳しくは、また別の記事にしたいと思っています。
私は「コナン君は年を取ると新一兄ちゃんになるか?」というテーマで課題に取り組みました。
最終課題は上手くできませんでしたが、勉強になったのは下記2点です。
①世の中の論文はTensor Flowで書かれたものが多い
アカデミックな世界では、インパクトファクターというどのぐらい引用されたかという指標が大事にされています。
また、深層学習の論文は自分の手法をstate-of-the-artと主張して、他の論文と比べてこれだけ俺の論文は優れている、というようなイキリ芸が多いです。
つまり、論文のソースコードが公開されていると追試ができる=引用数も増えるということで筆者と引用者でwin-winの関係を築くことができています。
しかし、深層学習をする環境が違うと、追試するハードルが高くなってしまいます。
そこで、ユーザ数が多いTensor Flowのコードで書かれたものがどんどん増えていくのではないか、と感じました。
自分がやりたいことに対して合うフレームワークが特になければ、Tensor Flowを使っていくのが良いのだろうなと思いましたし、ソフトウェア界でデファクトスタンダードとなっているプロトコル等はこのように確立されていったのだろうなと感じて面白かったです。
②オープンなコミュニティの力は強い
後述しますが、私は最終課題にgithubに上げられているコードを改変して使用しました。
そのとき、うまく動かなくて困ったのですが、同じように困っている人がIssueにいろいろ書いてくれていますので、なんとか動かせるところまでいきました。
このような一般的な話ではないようなものにもたくさんの人が関わっている世界が作られていることに驚きました。
以前から感じていましたが、オープンなコミュニティの力はやはり強いと思いましたし、自分もできる範囲で協力していきたいなと思った次第です。
それでは本題です。
1.テーマ選定
DL4USのカリキュラムで学んだことは大まかにいうと、CNN,RNN,GAN,DQNになります。
一番面白いなと感じたのは強化学習なのですが、強化学習は学んだように、結果が見えるまでにものすごく時間がかかります。自分のGPUがなく、iLect上の学習環境しかない私には、期限内に何かするのは難しいなと思いました。
なので、次に面白いと思ったGAN周りで何かできないかと思い、GANを学んでいるときに思ったコナン君の老化について取り組んでみようと考えました。
コナン君を知らない人のために述べておくと、コナン君は名探偵コナンという作品に登場するキャラクターで、悪い奴らに薬を飲まされ10歳若返った、という設定があります。なので、10歳年を取ったキャラデザイン(新一)も存在しますので、GANでできる10歳年取ったコナンくんと公式の10歳年を取った新一の顔を比較が可能なのです。
2.手法の選定
年を取らせる、という手法と言えば、Conditional GANです(下図は[1]より引用)。
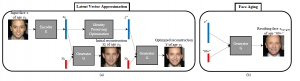
ざっくり言うと、ニューラルネットワークで入力画像を潜在ベクトル化して、それに年齢のラベルをくっつけて復元するという操作をGANの枠組みで学習させて、年を取らせたいときは、画像を潜在ベクトル化したものに、好きな年齢のラベルをくっつけて復元させる、というニューラルネットワークです。
この論文[1]の手法をまずはやってみようと思ったのですが、論文に書かれているデータセットの絞り込み方からして良くわかりませんでした。というのも、クリーンにしたデータセット、と書かれているだけだったからです。確かにデータセットを見ていると、明らかにアノテーションが合っていないデータや、使えそうもないデータが存在しました。また、筆者にメールで問い合わせたところ、正面を向いているデータだけに限ったというような回答を得ることができました。
つまり、データクレンジングが必須なデータセットで学習させた、という論文だった訳です。私は仕事をしながら課題をこなす必要がありましたし、データクレンジングからやると間に合わないのでは、という懸念があったので、このデータセットを使うのは難しいかなと思いました。
一方で、類似の論文で筆者がCAAEと呼んでいる手法[2]がありました。これはConditional GANとは異なりますが、似たような構成です。別記事でどういうものかまとめられれば、と考えています。こちらの論文を調査したところある程度整ったデータセットが公開されている上に、ソースコードも公開されていました!これだけ整っていればさすがに結果が出せると思ったので、こちらのデータセットと手法を使うことにしました。
3.データクレンジング
ある程度整っているといえども、変なデータは存在していました。
上図はレポートにも載せた画像なのですが、変なデータの例です。
目だけだったり、顔に文字が重なっていたり、どこかの村長みたいな顔をしたおっさんに5歳というラベルが付いていたりしました。
こういうデータが少し存在しても大局的には影響ないと思いますが、自分は生物実験をしていた人間ですので、このような少しでも不確定な要素は排除すべきという考えです。
ですので、25000枚ぐらいある画像を自力で眺めて、このような画像を300枚程度除きました。
画像処理をやっている人だとこのへんパパッとコードで書いて整理できちゃうような気もします。
4.結果が出るまで
最終課題をやっていた当時(2018年3月中旬)、githubで公開されていたコードはTensorFlow1.2向けでした(今(2018年5月中旬)はTensorFlow1.7向けのコードを筆者がアップロードしています、展開が速いですね)
一方で、iLectの環境はTensorFlow1.4でしたのでそのままでは動きませんでした。
具体的には、関数の引数が変わっていたり、Optimizerがうまく動かなかったり、です。
やっと動いた、と思ったらこの人のように結果が全部オレンジの画像になったりしました。
最終的にはTensorFlow1.4で導入されたAUTO_REUSEというものを利用し、Adam Optimizerをうまく動くようにしたことで、学習が進みました。
Issueにはライブラリの変更でうまくいくと書いてありましたが、私はうまくいかなかったので、愚直にコードをAUTO_REUSEを使うように変更しました。
5.結果
データセットにある画像を試しに入れてみると、学習を進めていくにつれて、そこそこ良さそうな結果が出ました。

上が入力画像、下にいくにつれて学習、右に行くほど、年を取っています。
これはそれなりの結果が出るのでは、と思いコナン君の画像を入れてみると惨敗・・・
左から入力画像、入力画像+10代での生成画像、右がこういう顔になって欲しい、という画像です。左と右の画像はグーグル画像検索から持ってきたものをImagemagickでサイズ整えたものです。怖い画像が生成されてしまいました・・・
他にも名探偵コナンの登場人物の灰原哀ちゃん等を入れてみましたが、怖い画像になってしまいました。。。
レポート出した当時は原因として、ニューラルネットの汎化性能が低いのでは?と書いて出してしまいましたが、今Issueで同じようなことを書いている人がいますので、私のコードがどこかおかしかった可能性もあると考えています。
6.まとめ
dl4usの最終課題のために、コナン君の顔を老けさせる、というテーマで取り組んでみましたが、残念ながらあまりうまくいきませんでした。が、最新の論文をいろいろ読めましたし(arxivは2018年登録の論文もすぐに読めていいですね)、github周りのエコシステム、課題解決のスピード感を体感することになったので良かったです。
7.付録
[1]https://arxiv.org/pdf/1702.01983.pdf
[2]https://arxiv.org/pdf/1702.08423.pdf
あと自分が改変したコードをforkしたレポジトリにコミットしてみましたが、今からやるなら普通に筆者のTensorFlow1.7のものを使ったほうが良いと思います。
https://github.com/kumazusa/Face-Aging-CAAE
ずさずさ
最新記事 by ずさずさ (全て見る)
- Azure Functions V1を使う - 2019年1月6日
- EventGridの使用を始めるときにつまずいたところ - 2018年12月2日
- サーバレス周りの話 - 2018年9月17日